Reproducibility with Jupyter Notebooks
Jupyter Notebooks designed to support reproducible research. It enables data people to craft easily shared computational narratives that mix code, results, and text
List All Relevant Dependencies
Reproducing analysis will require accessing not only code, but also any dependencies. I manage my dependencies explicitly from the start with pip’s requirements.txt to list all relevant dependencies (including their software versions).
Listing the versions of critical dependencies in the notebook itself (best done at the bottom) will ensure that, if used in isolation from its environment, the notebook still contains critical information to help other replicate results.
In notebooks, you can use a notebook extension such as watermark to explicitly print out your dependencies.
Share Your Data
Ideally, share your entire dataset alongside your notebooks. I used the word ideally as many datasets are too large or too sensitive to share this way. Host public copies of medium-sized, anonymized data in figshare (https://figshare.com/), zenodo (https://zenodo.org/). These data hosting services provide Digital Object Identifiers (doi) to uniquely and permanently identify datasets, an important aspect of reproducibility. Having access to a clearly-annotated notebook is of little use to reproducibility if the underlying data is locked away.
Strive for Zero Installation
To further lower barriers to reproducibility, use Binder to provide a zero-install environment to run your notebooks in the cloud You can also create a Docker image of your environment to ease setup.
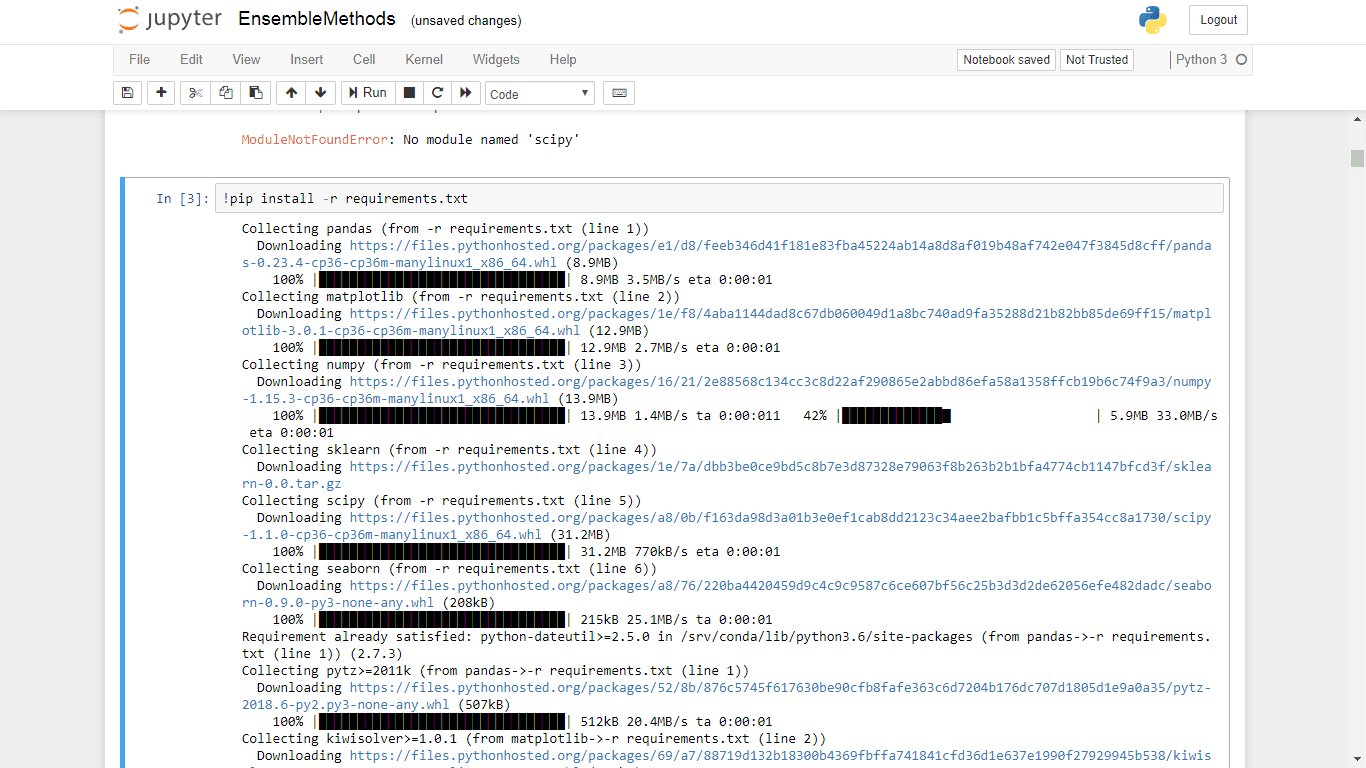
In this example, 6 different module of library software is require to re-produce the analysis. List out all the software library individually on a separate line in a requirements.txt and then type
!pip install -r requirements.txt
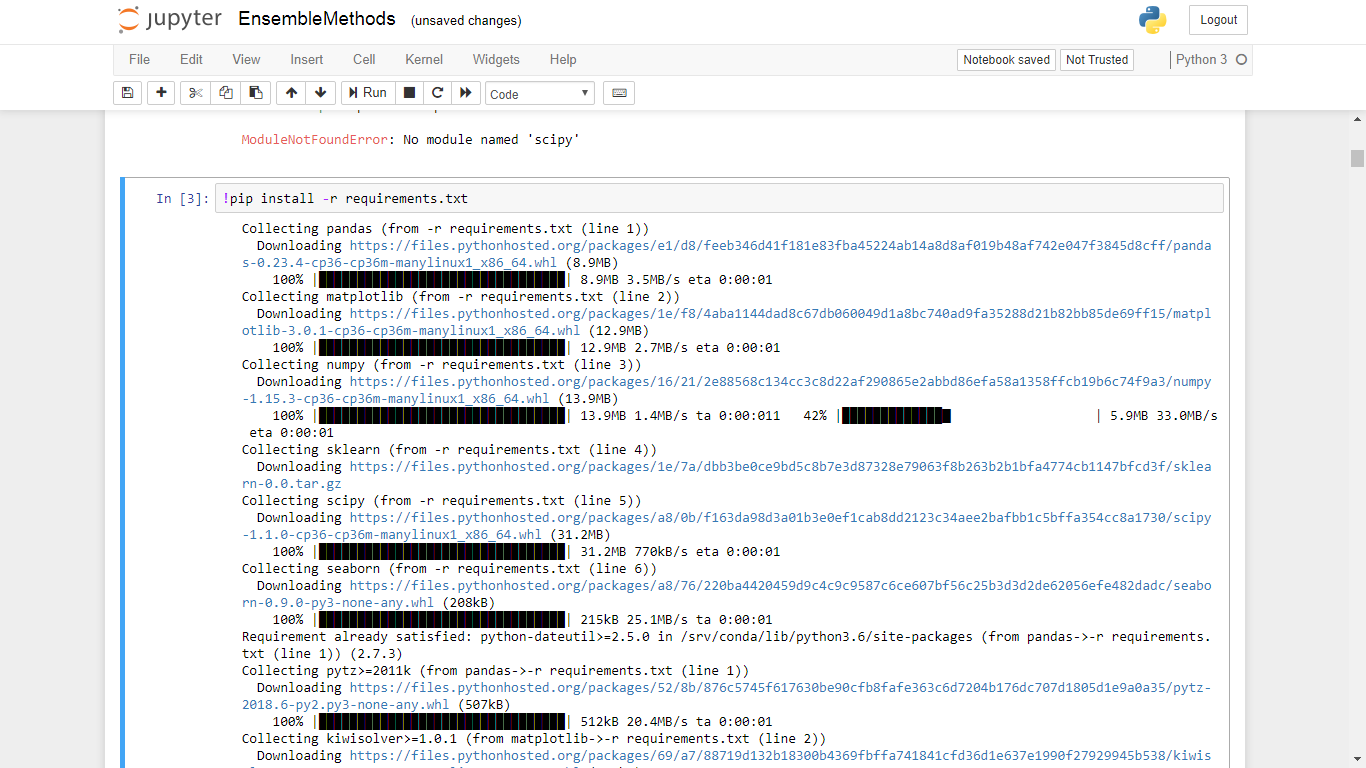
In one fell swoop, the six require software library are download and installed! All running in the cloud. No mess up on your PC system.
Diff, Merge, and Validate
Use version control
Jupyter Notebooks store both code and metadata about each cell as a text file in the JSON (JavaScript Object Notation) format. Version control systems compare differences in these JSON files, not differences in the user-friendly notebook GUI (graphical user interface). Because of this, reported differences between versions of a given notebook are usually difficult for users to find and understand, because they are expressed as changes in the abstruse JSON metadata for the notebook. To address this issue, use a notebook-specific diffing tool like nbdime that understands notebook structure and presents diffs in meaningful ways.
See also
Ten Simple Rules for Reproducible Research in Jupyter Notebooks